Filter by type:
Investigating Human Values in Online Communities
Human values play a vital role as an analytical tool in social sciences, enabling the study of diverse dimensions within society as a …

Investigating the Impact of Model Instability on Explanations and Uncertainty
Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly …

Understanding Fine-grained Distortions in Reports of Scientific Findings
Distorted science communication harms individuals and society as it can lead to unhealthy behavior change and decrease trust in …

Semantic Sensitivities and Inconsistent Predictions: Measuring the Fragility of NLI Models
Recent studies of the emergent capabilities of transformer-based Natural Language Understanding (NLU) models have indicated that they …
Grammatical Gender's Influence on Distributional Semantics: A Causal Perspective
How much meaning influences gender assignment across languages is an active area of research in modern linguistics and cognitive …

Invisible Women in Digital Diplomacy: A Multidimensional Framework for Online Gender Bias Against Women Ambassadors Worldwide
Despite mounting evidence that women in foreign policy often bear the brunt of online hostility, the extent of online gender bias …
Social Bias Probing: Fairness Benchmarking for Language Models
Large language models have been shown to encode a variety of social biases, which carries the risk of downstream harms. While the …
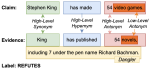
Factcheck-GPT: End-to-End Fine-Grained Document-Level Fact-Checking and Correction of LLM Output
The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the …
Quantifying Gender Bias Towards Politicians in Cross-Lingual Language Models
While the prevalence of large pre-trained language models has led to significant improvements in the performance of NLP systems, recent …
People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. …

PHD: Pixel-Based Language Modeling of Historical Documents
The digitisation of historical documents has provided historians with unprecedented research opportunities. Yet, the conventional …

Explaining Interactions Between Text Spans
Reasoning over spans of tokens from different parts of the input is essential for natural language understanding (NLU) tasks such as …
Why Should This Article Be Deleted? Transparent Stance Detection in Multilingual Wikipedia Editor Discussions
The moderation of content on online platforms is usually non-transparent. On Wikipedia, however, this discussion is carried out …
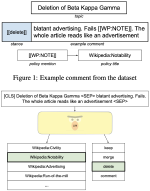
Thorny Roses: Investigating the Dual Use Dilemma in Natural Language Processing
Dual use, the intentional, harmful reuse of technology and scientific artefacts, is a problem yet to be well-defined within the context …

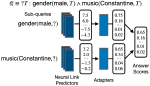
Adapting Neural Link Predictors for Complex Query Answering
Answering complex queries on incomplete knowledge graphs is a challenging task where a model needs to answer complex logical queries in …
Revisiting Softmax for Uncertainty Approximation in Text Classification
Uncertainty approximation in text classification is an important area with applications in domain adaptation and interpretability. One …
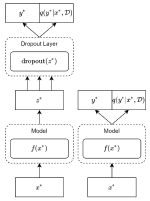
Detecting Harmful Content on Online Platforms: What Platforms Need vs. Where Research Efforts Go
The proliferation of harmful content on online platforms is a major societal problem, which comes in many different forms including …

Topic-Guided Sampling For Data-Efficient Multi-Domain Stance Detection
The task of Stance Detection is concerned with identifying the attitudes expressed by an author towards a target of interest. This task …
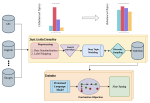
Multilingual Event Extraction from Historical Newspaper Adverts
NLP methods can aid historians in analyzing textual materials in greater volumes than manually feasible. Developing such methods poses …

Measuring Intersectional Biases in Historical Documents
Data-driven analyses of biases in historical texts can help illuminate the origin and development of biases prevailing in modern …

Faithfulness Tests for Natural Language Explanations
Explanations of neural models aim to reveal a model’s decision-making process for its predictions. However, recent work shows …

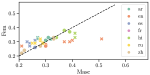
Probing Pre-Trained Language Models for Cross-Cultural Differences in Values
Language embeds information about social, cultural, and political values people hold. Prior work has explored social and potentially …

Measuring Gender Bias in West Slavic Language Models
Pre-trained language models have been known to perpetuate biases from the underlying datasets to downstream tasks. However, these …

Multi-View Knowledge Distillation from Crowd Annotations for Out-of-Domain Generalization
Selecting an effective training signal for tasks in natural language processing is difficult: expert annotations are expensive, and …

A Latent-Variable Model for Intrinsic Probing
The success of pre-trained contextualized representations has prompted researchers to analyze them for the presence of linguistic …
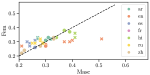
Generating Fluent Fact Checking Explanations with Unsupervised Post-Editing
Fact-checking systems have become important tools to verify fake and misguiding news. These systems become more trustworthy when …

Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings
Learning scientific document representations can be substantially improved through contrastive learning objectives, where the challenge …

Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically …

TempEL: Linking Dynamically Evolving and Newly Emerging Entities
In our continuously evolving world, entities change over time and new, previously non-existing or unknown, entities appear. We study …
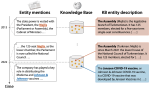
Machine Reading, Fast and Slow: When Do Models 'Understand' Language?
Two of the most fundamental challenges in Natural Language Understanding (NLU) at present are: (a) how to establish whether deep …

Can Edge Probing Tasks Reveal Linguistic Knowledge in QA Models?
There have been many efforts to try to understand what grammatical knowledge (e.g., ability to understand the part of speech of a …
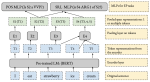
QA Dataset Explosion: A Taxonomy of NLP Resources for Question Answering and Reading Comprehension
Alongside huge volumes of research on deep learning models in NLP in the recent years, there has been also much work on benchmark …
A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives
Modern natural language processing (NLP) methods employ self-supervised pretraining objectives such as masked language modeling to …
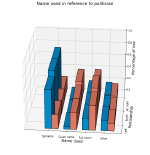
Quantifying Gender Biases Towards Politicians on Reddit
Despite attempts to increase gender parity in politics, global efforts have struggled to ensure equal female representation. This is …
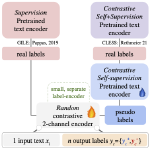
Habilitation Abstract: Towards Explainable Fact Checking
With the substantial rise in the amount of mis- and disinformation online, fact checking has become an important task to automate. This …
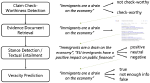
A Survey on Stance Detection for Mis- and Disinformation Identification
Detecting attitudes expressed in texts, also known as stance detection, has become an important task for the detection of false …

Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages …
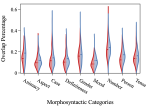
Counterfactually Augmented Data and Unintended Bias: The Case of Sexism and Hate Speech Detection
Counterfactually Augmented Data (CAD) aims to improve out-of-domain generalizability, an indicator of model robustness. The improvement …

Fact Checking with Insufficient Evidence
Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is …

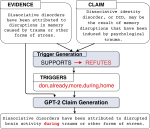
Generating Scientific Claims for Zero-Shot Scientific Fact Checking
Automated scientific fact checking is difficult due to the complexity of scientific language and a lack of significant amounts of …

Multi3Generation: Multi-task, Multilingual, Multi-Modal Language Generation
This paper presents the Multitask, Multilingual, Multimodal Language Generation COST Action – Multi3Generation (CA18231), an …
Multi-Sense Language Modelling
The effectiveness of a language model is influenced by its token representations, which must encode contextual information and handle …
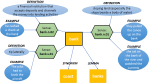
Few-Shot Cross-Lingual Stance Detection with Sentiment-Based Pre-Training
The goal of stance detection is to determine the viewpoint expressed in a piece of text towards a target. These viewpoints or contexts …
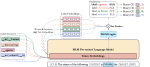
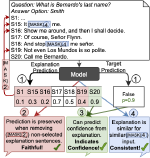
Diagnostics-Guided Explanation Generation
Explanations shed light on a machine learning model’s rationales and can aid in identifying deficiencies in its reasoning …
A Survey on Gender Bias in Natural Language Processing
While the prevalence of large pre-trained language models has led to significant improvements in the performance of NLP systems, recent …

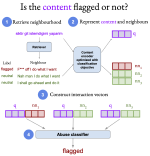
A Neighbourhood Framework for Resource-Lean Content Flagging
We propose a novel framework for cross-lingual content flagging with limited target-language data, which significantly outperforms …
Contrastive Text Pretraining for Zero to Few-Shot Long-Tail Learning
For natural language processing (NLP) tasks such as sentiment or topic classification, currently prevailing approaches heavily rely on …

Longitudinal Citation Prediction using Temporal Graph Neural Networks
Citation count prediction is the task of predicting the number of citations a paper has gained after a period of time. Prior work …
Information fusion as an integrative cross-cutting enabler to achieve robust, explainable, and trustworthy medical artificial intelligence
Medical artificial intelligence (AI) systems have been remarkably successful, even outperforming human performance at certain tasks. …

Time-Aware Evidence Ranking for Fact-Checking
Truth can vary over time. Therefore, fact-checking decisions on claim veracity should take into account temporal information of both …
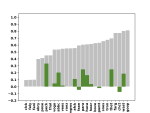
Semi-Supervised Exaggeration Detection of Health Science Press Releases
Public trust in science depends on honest and factual communication of scientific papers. However, recent studies have demonstrated a …
How Does Counterfactually Augmented Data Impact Models for Social Computing Constructs?
As NLP models are increasingly deployed in socially situated settings such as online abusive content detection, ensuring these models …

Cross-Domain Label-Adaptive Stance Detection
Stance detection concerns the classification of a writer’s viewpoint towards a target. There are different task variants, e.g., …
Joint Emotion Label Space Modelling for Affect Lexica
Emotion lexica are commonly used resources to combat data poverty in automatic emotion detection. However, methodological issues emerge …

Determining the Credibility of Science Communication
Most work on scholarly document processing assumes that the information processed is trust-worthy and factually correct. However, this …
Inducing Language-Agnostic Multilingual Representations
Cross-lingual representations have the potential to make NLP techniques available to the vast majority of languages in the world. …
Is Sparse Attention more Interpretable?
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet …

CiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding
Scientific document understanding is challenging as the data is highly domain specific and diverse. However, datasets for tasks with …
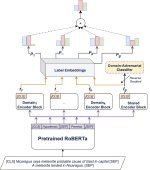
Multi-Hop Fact Checking of Political Claims
Recently, novel multi-hop models and datasets have been introduced to achieve more complex natural language reasoning with neural …
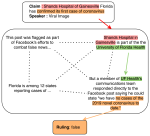
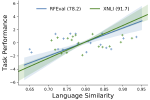
Does Typological Blinding Impede Cross-Lingual Sharing?
Bridging the performance gap between high- and low-resource languages has been the focus of much previous work. Typological features …
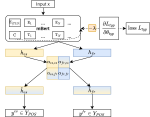
Towards Explainable Fact Checking
The past decade has seen a substantial rise in the amount of mis- and disinformation online, from targeted disinformation campaigns to …

University of Copenhagen Participation in TREC Health Misinformation Track 2020
In this paper, we describe our participation in the TREC Health Misinformation Track 2020. We submitted 11 runs to the Total Recall …


Transformer Based Multi-Source Domain Adaptation
In practical machine learning settings, the data on which a model must make predictions often come from a different distribution than …
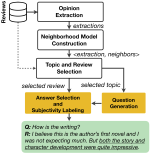
SubjQA: A Dataset for Subjectivity and Review Comprehension
Subjectivity is the expression of internal opinions or beliefs which cannot be objectively observed or verified, and has been shown to …
Generating Label Cohesive and Well-Formed Adversarial Claims
Adversarial attacks reveal important vulnerabilities and flaws of trained models. One potent type of attack are universal adversarial …
A Diagnostic Study of Explainability Techniques for Text Classification
Recent developments in machine learning have introduced models that approach human performance at the cost of increased architectural …

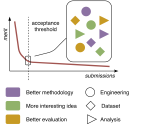
What Can We Do to Improve Peer Review in NLP?
Peer review is our best tool for judging the quality of conference submissions, but it is becoming increasingly spurious. We argue that …

Unsupervised Evaluation for Question Answering with Transformers
It is challenging to automatically evaluate the answer of a QA model at inference time. Although many models provide confidence scores, …
Disembodied Machine Learning: On the Illusion of Objectivity in NLP
Machine Learning (ML) seeks to identify and encode bodies of knowledge within provided datasets. However, data encodes subjective …
TX-Ray: Quantifying and Explaining Model-Knowledge Transfer in (Un-)Supervised NLP
While state-of-the-art NLP explainability (XAI) methods focus on supervised, per-instance end or diagnostic probing task evaluation[4, …
Generating Fact Checking Explanations
This paper provides the first study of how fact checking explanations can be generated automatically based on available claim context, …

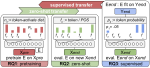
2kenize: Tying Subword Sequences for Chinese Script Conversion
We propose a novel Chinese character conversion model that can disambiguate between mappings and convert between the two scripts. The …
Semantic Textual Similarity of Sentences with Emojis
In this paper, we extend the task of semantic textual similarity to include sentences which contain emojis. Emojis are ubiquitous on …
Back to the Future -- Sequential Alignment of Text Representations
Language evolves over time in many ways relevant to natural language processing tasks. For example, recent occurrences of tokens …
MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims
We contribute the largest publicly available dataset of naturally occurring factual claims for the purpose of automatic claim …

Mapping (Dis-)Information Flow about the MH17 Plane Crash
Digital media enables not only fast sharing of information, but also disinformation. One prominent case of an event leading to …

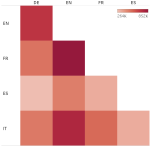
Retrieval-Based Goal-Oriented Dialogue Generation
Task oriented dialogue systems rely heavily on specialized dialogue state tracking (DST) modules for dynamically predicting user intent …
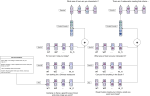
Domain Transfer in Dialogue Systems without Turn-Level Supervision
Task oriented dialogue systems rely heavily on specialized dialogue state tracking (DST) modules for dynamically predicting user intent …
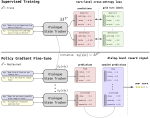
Transductive Auxiliary Task Self-Training for Neural Multi-Task Models
Multi-task learning and self-training are two common ways to improve a machine learning model’s performance in settings with …


Uncovering Probabilistic Implications in Typological Knowledge Bases
The study of linguistic typology is rooted in the implications we find between linguistic features, such as the fact that languages …
Proceedings of The Fourth Workshop on Representation Learning for NLP
The workshop has a focus on vector space models of meaning, compositionality, and the application of deep neural networks and spectral …
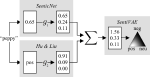

Issue Framing in Online Discussion Fora
In online discussion fora, speakers often make arguments for or against something, say birth control, by highlighting certain aspects …

What do Language Representations Really Represent?
A neural language model trained on a text corpus can be used to induce distributed representations of words, such that similar words …
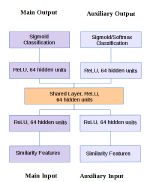
Latent multi-task architecture learning
Multi-task learning (MTL) allows deep neural networks to learn from related tasks by sharing parameters with other networks. In …
A strong baseline for question relevancy ranking
The best systems at the SemEval-16 and SemEval-17 community question answering shared tasks – a task that amounts to question …
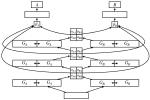
Parameter sharing between dependency parsers for related languages
Previous work has suggested that parameter sharing between transition-based neural dependency parsers for related languages can lead to …
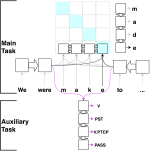
Copenhagen at CoNLL--SIGMORPHON 2018: Multilingual Inflection in Context with Explicit Morphosyntactic Decoding
This paper documents the Team Copenhagen system which placed first in the CoNLL–SIGMORPHON 2018 shared task on universal …
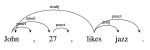
Nightmare at test time: How punctuation prevents parsers from generalizing
Punctuation is a strong indicator of syntactic structure, and parsers trained on text with punctuation often rely heavily on this …
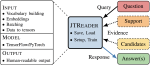
Jack the Reader – A Machine Reading Framework
Many Machine Reading and Natural Language Understanding tasks require reading supporting text in order to answer questions. For …
Proceedings of The Third Workshop on Representation Learning for NLP
The workshop has a focus on vector space models of meaning, compositionality, and the application of deep neural networks and spectral …
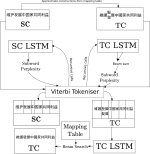
Character-level Supervision for Low-resource POS Tagging
Neural part-of-speech (POS) taggers are known to not perform well with little training data. As a step towards overcoming this problem, …
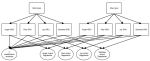
From Phonology to Syntax: Unsupervised Linguistic Typology at Different Levels with Language Embeddings
A core part of linguistic typology is the classification of languages according to linguistic properties, such as those detailed in the …

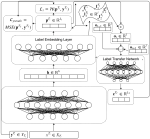
KU-MTL at SemEval-2018 Task 1: Multi-task Identification of Affect in Tweets
We take a multi-task learning approach to the shared Task 1 at SemEval-2018. The general idea concerning the model structure is to use …
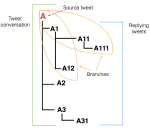
Discourse-Aware Rumour Stance Classification in Social Media Using Sequential Classifiers
Rumour stance classification, defined as classifying the stance of specific social media posts into one of supporting, denying, …
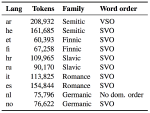
Tracking Typological Traits of Uralic Languages in Distributed Language Representations
Although linguistic typology has a long history, computational approaches have only recently gained popularity. The use of distributed …

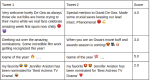
Generalisation in Named Entity Recognition: A Quantitative Analysis
Named Entity Recognition (NER) is a key NLP task, which is all the more challenging on Web and user-generated content with their …
A simple but tough-to-beat baseline for the Fake News Challenge stance detection task
Identifying public misinformation is a complicated and challenging task. An important part of checking the veracity of a specific claim …


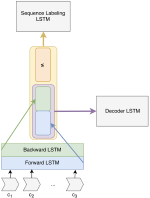
Turing at SemEval-2017 Task 8: Sequential Approach to Rumour Stance Classification with Branch-LSTM
This paper describes team Turing’s submission to SemEval 2017 RumourEval: Determining rumour veracity and support for rumours …
Sequential Approach to Rumour Stance Classification
Rumour stance classification is a task that involves identifying the attitude of Twitter users towards the truthfulness of the rumour …
An Unsupervised Data-driven Method to Discover Equivalent Relations in Large Linked Datasets
We propose a novel similarity measure able to cope with unbalanced population of schema elements, an unsupervised technique to …
